Project: E-Commerce CSV-to-Parquet Optimization
Summary
At an e-commerce company, online retailer of locally sourced gourmet foods and artisanal home goods, targeting Spanish consumers and EU tourists, supplier inventory CSVs were causing slow analytics and schema inconsistencies. I built a pipeline that auto-converts them to Parquet and resolves messy schemas, cutting Athena costs by 60% and speeding up queries. This let the team adjust pricing strategies faster.
Business Problem
An e-commerce startup receives daily CSV inventory feeds from 20+ small suppliers. While CSV was initially simple, performance and cost issues have compounded as data volume grows.
- Slow, expensive queries: Athena scans hundreds of gigabytes of CSVs, making even simple queries take minutes and cost hundreds of euros per month.
- Data inconsistencies: Suppliers use mixed encodings (UTF-8 vs. Windows-1252), varied schemas, and inconsistent date formats.
Current Data Sources & Architecture
- S3 (raw CSV bucket): Daily CSV drops from suppliers via email or WooCommerce export.
- PostgreSQL: Product catalog & customer orders on an EC2 instance (inventory kept separate).
- Google Sheets: Manual pricing adjustments by finance team.
- Google Analytics: Website behavior tracking.
Table 1
| sku |
|---|
| product_name |
| current_stock |
| price_eur |
| discount_price |
| reorder_threshold |
| last_delivery_date |
Table 2
| product_id |
|---|
| product_name |
| current_stock |
| price |
| discount_price |
| lead_time_days |
| reorder_threshold |
| last_delivery_date |
| supplier_notes |
Sample supplier CSV schema and common inconsistencies.
Pain Points
- Query performance: “Which gourmet products are below reorder threshold?” takes ~3 minutes against 200+ CSVs.
- Manual fixes: Staff spend hours correcting encoding and timestamp errors.
- Cost overruns: €300+/month in Athena scan fees for inventory data alone.
- Lost sales & inventory waste: Delayed markdowns and reorder alerts lead to stockouts (e.g., saffron during holiday season) and overordering.
Proposed Solution
Implement a serverless ETL pipeline to convert raw CSVs into partitioned Parquet files, leveraging AWS Glue, Lambda, and Spark for scalability and cost efficiency.
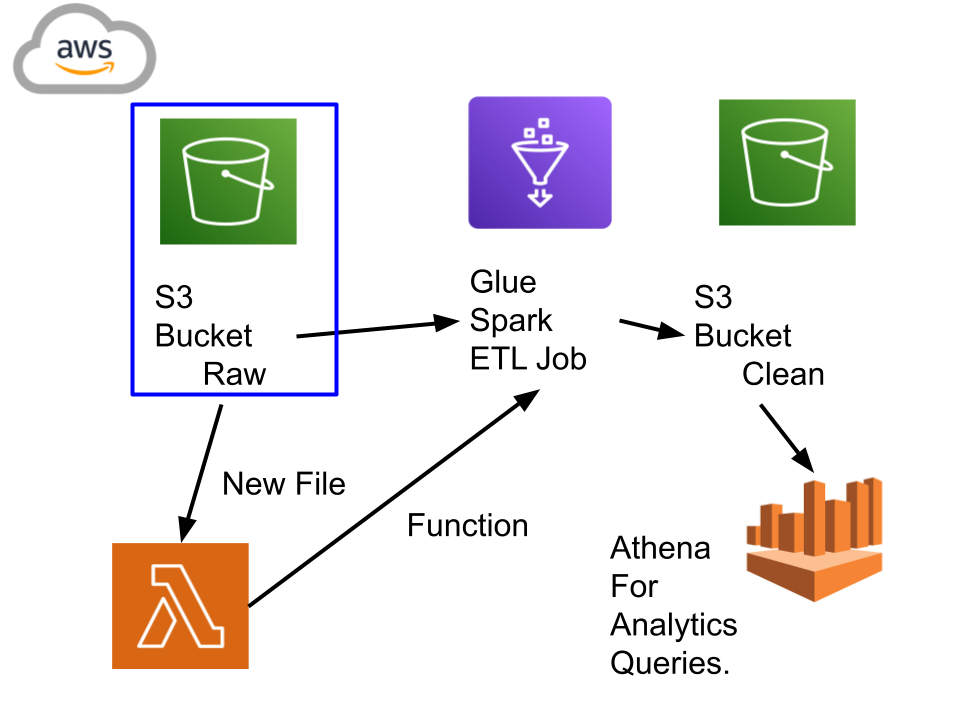
Key Components
- AWS Lambda: Detects new CSV uploads and invokes Glue jobs.
- AWS Glue Crawler: Auto-detects schema variations and updates the Data Catalog.
- Glue Spark ETL: Converts CSV to Parquet for files >1 GB in parallel, writing to a partitioned S3 prefix.
- Partition Strategy: By
product_category,warehouse_location, anddateto minimize scan footprint. - Athena: Queries against the optimized Parquet dataset for fast, low-cost analytics.
Business Impact
- Performance: Query times reduced from minutes to seconds (e.g., low-stock reports in < 5 s).
- Cost Savings: Athena scan volume drops by ~90%, cutting inventory-related spend by ~€200/month.
- Data Quality: Automated schema discovery and centralized catalog ensure consistency across suppliers.
Thanks for reading! 🧑💻💕